Основные типы – 2.6. Основные типы данных
Тип данных — Википедия
Материал из Википедии — свободной энциклопедии
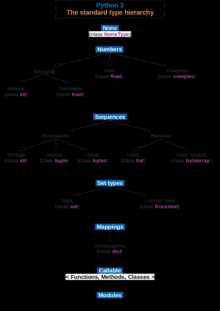
Тип данных (тип) — множество значений и операций на этих значениях (IEEE Std 1320.2-1998)[1].
Другие определения:
- Тип данных — класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применены (ISO/IEC/IEEE 24765-2010)[2].
- Тип данных — категоризация абстрактного множества возможных значений, характеристик и набор операций для некоторого атрибута (IEEE Std 1320.2-1998)[3].
- Тип данных — категоризация аргументов операций над значениями, как правило, охватывающая как поведение, так и представление (ISO/IEC 19500-2:2003)[4].
- Тип данных — допустимое множество значений[5].
Тип определяет возможные значения и их смысл, операции, а также способы хранения значений типа. Изучается теорией типов. Неотъемлемой частью большинства языков программирования являются системы типов, использующие типы для обеспечения той или иной степени типобезопасности.
Тип данных характеризует одновременно:
- множество допустимых значений, которые могут принимать данные, принадлежащие к этому типу;
- набор операций, которые можно осуществлять над данными, принадлежащими к этому типу.
Первое свойство можно рассматривать как теоретико-множественное определение понятия типа; второе — как процедурное (или поведенческое) определение.
Кроме этого, в программировании используется низкоуровневое определение типа — как заданных размерных и структу
ru.wikipedia.org
Основные типы данных
О типах данных по-быстрому
Цель этого подмодуля – по-быстрому рассказать о основных типах данных и дать их потрогать. Позже мы познакомимся с типами куда обстоятельнее.
Целые и вещественные числа
Числа – и в Африке числа. С ними можно производить арифметические действия. Всё просто:2 + 2 # 4 3 + 2.5 # 5.5 6 / 2 # 3 2 ** 3 # 8
Решётка – это знак комментария в Питоне, а в этом туториале результат работы команды указан на той же строчке за комментарием.
Исправьте ошибку. Программа должна выводить число value в кубе.
value = 5 print(value * 3)
value = 5 print(value ** 3)
Строки
Помимо чисел в Питоне есть строки с богатым набором встроенных функций. С ними просто и удобно работать:
'hello' # строковая константа "hello" # тип кавычек не имеет значения hello[1] # 'e' 'hello' + ' ' + 'world' # 'hello world' 'blah ' * 3 # 'blah blah blah '
У них много встроенных функций:
'hello '.strip() # 'hello'
'hello world'.upper() # 'HELLO WORLD'
len('hello') # 5
'wor' in 'hello world' # True (входит ли "wor" в строку "hello world")
'hello world'.startswith('hel') # True (начинается ли "hello world" c "hel")
Ещё можно превращать строку в список, список в строку, получать подстроку и по-разному форматировать значения, но об этом позже.
Список
Список – последовательность элементов. Ограничения на длину нет. Элементы могут быть разных типов, даже другими списками. Выглядит он так:
[1, 2, 3] # в квадратных скобках, элементы через запятую digits = [4, 5, 6] # переменная, в которой живёт список digits[0] # 4 (нумерация с нуля) digits[1] = 22 # теперь в списке digits на втором месте стоит 22 digits.append(8) # а теперь в конец добавилась восьмёрка
Из списка надо часто получить подсписок: несколько первых элементов, последних, что-то из середины. Это называется срезами и позволяет делать много чего. Вот самые простые срезы:
squares = [1, 4, 9, 16, 25, 36, 49] squares[1:3] # [4, 9] (элементы со второго по третий) squares[:4] # [1, 4, 9, 16] (элементы с начала до четвёртого) squares[4:] # [25, 36, 49] (элементы с пятого до конца) squares[1:6:2] # [4, 16, 36] (элементы со второго до шестого с шагом два)
devman.org
Основные типы данных
Количество просмотров публикации Основные типы данных – 492
Переменные и константы. Типы данных
Ошибки
Ошибки, допускаемые при написании программ, разделяют на синтаксические и логические.
Синтаксические ошибки – нарушение формальных правил написания программы на конкретном языке, обнаруживаются на этапе трансляции и бывают легко исправлены.
Программа, содержащая синтаксическую ошибку, не должна быть запущена. При попытке ее компиляции выдается сообщение, обычно содержащее указание того места в тексте, “дочитав” до которого, компилятор заметил ошибку; сама ошибка должна быть как в данном месте, так и выше него (часто – в предыдущей строке).
Логические ошибки делят на ошибки алгоритма и семантические ошибки – бывают найдены и исправлены только разработчиком программы.
Причина ошибки алгоритма – несоответствие построенного алгоритма ходу получения конечного результата сформулированной задачи.
Причина семантической ошибки – неправильное понимание смысла (семантики) операторов языка.
Программа, содержащая логическую ошибку, должна быть запущена. При этом она либо выдает неверный результат, либо даже завершается “аварийно” из-за попытки выполнить недопустимую операцию (к примеру, деление на 0) – в таком случае выдается сообщение об ошибке времени выполнения. Поиск места в программе, содержащего логическую ошибку, является непростой задачей; он носит название отладки программы.
Для программиста на языке Си память компьютера представляется как набор ячеек, каждая из которых принято называть переменной, или константой, исходя из того, меняется ее значение в процессе работы или нет. Каждая переменная имеет имя (идентификатор, ID). Константа может иметь или не иметь имени.
Род информации, которую способна хранить ячейка, определяется ее типом.
Данные в языке Си разделяются на две категории: простые (скалярные), будем их называть базовыми, и сложные (составные) типы данных.
Тип данных определяет:
‣‣‣внутреннее представление данных в оперативной памяти;
‣‣‣совокупность значений (диапазон), которые могут принимать данные этого типа;
‣‣‣набор операций, которые допустимы над такими данными.
Основные типы базовых данных: целый – int, вещественный с одинарной точностью –
В свою очередь, данные целого типа бывают короткими – short, а также длинными – long . Вместе с тем, при любой длине данные целых и символьного типов бывают знаковыми – signed либо беззнаковыми – unsigned (по умолчанию они считаются знаковыми, в связи с этим слово signed необязательно и обычно опускается). Вещественные же данные могут иметь удвоенную точность – double.
Сложные типы данных – массивы, структуры – struct, объединения или смеси – union.
Данные целых и вещественных типов находятся в определенных диапазонах, т.к. занимают разный объём оперативной памяти. Вещественные типы при этом обладают еще конечной точностью хранения данных, ᴛ.ᴇ. верно хранят лишь первые несколько цифр числа; для хранения остальных (чье количество бывает даже бесконечным – к примеру, у числа π , или у числа ⅓ ) не хватает места. В Табл. 1. приведены свойства различных типов для системы программирования C++ Builder. В других системах программирования, поддерживающих язык Си, может отличаться размер того или иного конкретного типа, к примеру int, и соответственно будет отличаться его допустимый диапазон значений (к примеру, тип long int может превосходить по размеру тип int). При этом последовательность возрастания размеров и точности для каждой группы типов всегда одинакова:
char ≤ short int ≤ int ≤ long int ≤ long long int
float ≤ double ≤ long double
Таблица 1.
| Тип данных | Размер (байт) | Диапазон значений | Точность, десятичных знаков |
| сhar | -128 … 127 | ||
| unsigned сhar | 0 … 255 | ||
| short int | -215… 215–1 (-32768…32767) | ||
| int | -231…231–1 (-2147483648…2147483647) | ||
| long int | -231…231–1 (-2147483648…2147483647) | ||
| long long int | –263… 263–1 (примерно ) | ||
| unsigned short int | 0…216–1 (0…65535) | ||
| unsigned int | 0…232–1 (0…4294967295) | ||
| unsigned long int | 0…232–1 (0…4294967295) | ||
| float | ±3,14*10-38…±3,14*1038 | 7-8 | |
| double | ±1,7 *10-308… ±1,7 *10308 | 15-16 | |
| long double | ± 1,1 * 10-4932… ± 1,1 * 104932 | 19-20 |
Заметим, что для целочисленных типов данных, чье название содержит слово int и еще какое-либо слово перед ним, слово int можно не писать, и обычно оно опускается (в Табл.1 необязательное int указано мелким шрифтом).
2.2. Декларация (объявление) объектов
Все объекты (переменные, функции и пр.), с которыми работает программа, в языке Си крайне важно декларировать, ᴛ.ᴇ. объявить компилятору об их присутствии в программе. При этом возможны две формы декларации:
– описание, не приводящее к выделению памяти;
– определение, при котором под объект будет выделен объём оперативной памяти, в соответствии с его типом; в данном случае объект можно сразу инициализировать, ᴛ.ᴇ. задать его начальное значение.
Кроме констант, которые можно задавать в исходном тексте, все объекты программы должны быть явно декларированы по следующему формату:
<атрибуты> <список ID объектов>;
элементы списка разделяются запятыми, а атрибуты – разделителями. К примеру: int i,j,k; float a,b;
Объекты программы в общем случае имеют следующие атрибуты:
<класс памяти> – характеристика способа размещения объектов в памяти (статическая, динамическая), определяет область видимости и время жизни переменной (по умолчанию – auto), данные атрибуты будут рассмотрены позже;
<тип> – характеристика механизма интерпретации данных, ᴛ.ᴇ. это совокупность информации о том, сколько объекту нужно выделить памяти, какой вид имеет представление информации и какие действия над ней допустимы (по умолчанию – int).
Класс памяти и тип – атрибуты необязательные и могут отсутствовать, тогда их значения установятся по умолчанию.
Примеры декларации простых переменных:
int i,j,k;
char r;
double gfd;
referatwork.ru
Основные типы микропроцессоров: разновидности, архитектура/структура, 8-16-32 разрядные
 Основные типы микропроцессоров
Основные типы микропроцессоров
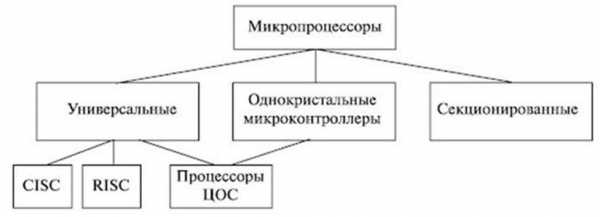 Основные типы микропроцессоров
Основные типы микропроцессоровВыпускаемые различными производителями процессоры делятся на отдельные типы в соответствии с используемыми классификационными признаками. Одним из важнейших признаков помимо вида архитектуры является функциональное назначение. По этому признаку, микропроцессоры разбивают на два больших класса:
- процессоры общего назначения, или универсальные микропроцессоры;
- специализированные процессоры, среди которых наиболее широкое распространение получили микроконтроллеры, цифровые сигнальные процессоры и медийные процессоры. Рассмотрим особенности этих процессоров.
Микропроцессоры общего назначения
Этот класс процессоров предназначен для решения широкого круга задач обработки разнообразной информации и находит применение в персональных компьютерах, рабочих станциях, серверах и других цифровых системах массового применения. К универсальным процессорам относят 32–разрядные микропроцессоры (хотя некоторые микропроцессоры этого класса имеют 64–разрядную или 128–разрядную структуру), которые изготавливаются по самой современной промышленной технологии, обеспечивающей максимальную частоту функционирования.
Большинство типов микропроцессоров этого класса имеют CISC–архитектуру, поскольку используют набор разноформатных команд с различными способами адресации.
В их внутренней структуре может содержаться RISC–ядро, выполняющее преобразование поступивших команд в оследовательность простых RISC–операций. Некоторые типы микропроцессоров этого класса непосредственно реализует RISC–архитектуру.
В ряде последних разработок (Itanium РА8500) успешно используются принципы VLIW–архитектуры.
Практически все современные универсальные микропроцессоры используют гарвардскую архитектуру с разделением потоков команд и данных при помощи отдельных блоков внутренней кэш–памяти. В большинстве случаев они имеют суперскалярную структуру (несколько операционных устройств, осуществляющих одновременную обработку данных) с несколькими исполнительными конвейерами (до 10 в современных моделях), каждый из которых содержит до 20 ступеней.
Микроконтроллеры. Этот класс специализированных микропроцессоров ориентирован на применение в качестве устройств или систем управления, встраиваемых в разнообразную (в том числе и бытовую) аппаратуру. Номенклатура выпускаемых микроконтроллеров исчисляется несколькими тысячами типов, а общий годовой объем их выпуска составляет миллиарды экземпляров.
Особенностью микроконтроллеров является размещение на одном кристалле, помимо центрального процессора, внутренней памяти и большого набора периферийных устройств.
В состав периферийных устройств обычно входят от одного до восьми 8–разрядных параллельных портов ввода–вывода данных, один или два последовательных порта, таймерный блок, аналого–цифровой преобразователь, а также такие специализированные устройства, как блок формирования сигналов с широтно–импульсной модуляцией, контроллер жидкокристаллического дисплея и ряд других. Благодаря использованию внутренней памяти и периферийных устройств реализуемые на базе микроконтроллеров системы управления содержат минимальное количество дополнительных компонентов.
Для удовлетворения запросов потребителей выпускается большая номенклатура микроконтроллеров, которые принято подразделять на 8–, 16– и 32–разрядные.
8–разрядные микроконтроллеры
8–разрядные микроконтроллеры являются наиболее простыми и дешевыми изделиями этого класса, ориентированными на использование в относительно несложных устройствах массового выпуска. Микроконтроллеры этой группы обычно выполняют относительно небольшой набор команд (50–100), использующих наиболее простые способы адресации. Основными областями их применения являются промышленная автоматика, автомобильная электроника, измерительная техника, теле–, видео– и аудиотехника, средства связи, бытовая аппаратура.
Для 8–разрядных микроконтроллеров характерна гарвардская архитектура:
- с отдельной внутренней памятью для хранения программ, в качестве которой используются масочно–программируемые ПЗУ (ROM), однократно программируемое ПЗУ (PROM) или электрически репрограммируемое ПЗУ (EPROM, EEPROM или Flash) с объемом от нескольких единиц до десятков килобайт;
- с отдельной внутренней памятью для хранения данных, в качестве которой используется регистровый блок, организованный в виде нескольких регистровых банков, или ОЗУ. Ее объем составляет от нескольких десятков байт до нескольких килобайт.
В случае необходимости имеется возможность дополнительно подключать внешнюю память команд и данных объемом до 64–256 Кбайт и более.
Для повышения производительности во многих моделях 8–разрядных микроконтроллеров реализованы принципы RISC–архитектуры, обеспечивающие выполнение большинства команд за один такт машинного времени.
16–разрядные микроконтроллеры
16–разрядные микроконтроллеры помимо повышенной разрядности обрабатываемых данных характеризуются:
- более высокой производительностью;
- расширенной системой команд и способов адресации;
- увеличенным набором регистров и объемом адресуемой памяти;
- возможностью расширения объема памяти программ и данных до нескольких мегабайт путем подключения внешних микросхем памяти;
- программной совместимостью с 8–разрядными микроконтроллерами и другими возможностями.
Основные области применения — сложная промышленная автоматика, телекоммуникационная аппаратура, медицинская и измерительная техника.
32–разрядные микроконтроллеры
32–разрядные микроконтроллеры ориентированы на применение в системах управления сложными объектами промышленной автоматики (средствами комплексной автоматизации производства, робототехнические устройствами, двигателями и др.), в контрольно–измерительной аппаратуре, телекоммуникационном оборудовании и других сложных устройствах. 32–разрядные микроконтроллеры содержат:
- высокопроизводительный CISC– или RISC–процессор, соответствующий по своим возможностям младшим моделям микропроцессоров общего назначения. Например, в микроконтроллерах компании Intel используется процессор i386, а в микроконтроллерах компании Motorola — процессор 680×0. Введение этих процессоров в состав микроконтроллеров позволяет использовать в соответствующих системах управления огромный объем прикладного и системного программного обеспечения, созданный ранее для соответствующих персональных компьютеров. Некоторые типы микроконтроллеров содержат несколько исполнительных конвейеров, образующих суперскалярную структуру;
- внутреннюю память команд емкостью до десятков килобайт и память данных емкостью до нескольких килобайт;
- средства для подключения внешней памяти объемом до 16 Мбайт и выше;
- набор сложных периферийных устройств — таймерный процессор, коммуникационный процессор, модуль последовательного обмена и ряд других. Во внутренней структуре этих микроконтроллеров реализуется принстонская или гарвардская архитектура.
Цифровые сигнальные процессоры
Этот класс специализированных микропроцессоров предназначен для цифровой обработки поступающих аналоговых сигналов в реальном времени. Архитектура цифровых сигнальных процессоров (ЦСП) ориентирована на быстрое выполнение последовательности операций умножения–сложения с накоплением промежуточного результата в регистре–аккумуляторе, что обусловлено особенностью алгоритмов обработки аналоговых сигналов. Поэтому набор команд этих процессоров содержит специальные команды MAC (Multiplication with Accumulation — умножение с накоплением), реализующие эти операции.
Значение оцифрованного аналогового сигнала может быть представлено в виде числа с фиксированной или с плавающей точкой. В соответствии с этим ЦСП делятся на два класса:
- на процессоры, обрабатывающие числа с фиксированной точкой. К этому классу относятся более простые и дешевые ЦСП, которые обычно обрабатывают 16– или 24–разрядные операнды, представленные в виде правильной дроби. Однако ограниченная разрядность в ряде случаев не позволяет обеспечить необходимую точность результатов;
- на процессоры, обрабатывающие числа с плавающей точкой. Процессоры этого класса проводят вычисления над 32– и 40–разрядными операндами и обеспечивают более высокую точность результатов.
Для повышения производительности при выполнении специфических операций обработки сигналов в большинстве ЦСП реализуется гарвардская архитектура с использованием отдельных шин для передачи адресов, команд и данных. В ряде ЦСП нашли применение также некоторые черты
VLIW–архитектуры, для которой характерно совмещение в одной команде нескольких операций. Такое совмещение обеспечивает обработку имеющихся данных и одновременную загрузку в исполнительный конвейер новых данных для последующей обработки.
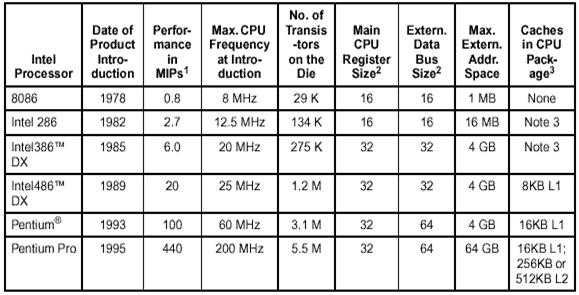
Медийные процессоры
Этот тип процессоров предназначен для обработки аудио–сигналов, графики, видеоизображений, а также для решения ряда коммуникационных задач в мультимедиа–компьютерах, игровых приставках, бытовых приборах и др.
Аппаратную поддержку операций с новыми типами данных, характерными для обработки видео– и звуковой информации обеспечивают универсальные процессоры с мультимедийным расширением набора команд: Pentium ММХ, UltraSPARC, Cyrix 6х86МХ (М2), AMD–K6 и др. Однако, когда мультимедийные операции доминируют над традиционными числовыми операциями, больший эффект дает использование мультимедийных микропроцессоров. Их архитектура представляет собой некоторый гибрид архитектурных решений сигнальных и универсальных процессоров. Производством медиа–процессоров заняты компании MicroUnity (процессор Mediaprocessor), Philips (TriMedia), Chromatic Research (Mpact Media Engine) и др.
Структура и режимы работы микропроцессорной системы
Микропроцессор в совокупности с модулями ввода и вывода информации, интерфейса и памяти образует простейшую микропроцессорную систему. Среди микропроцессорных систем важное место занимают системы общего назначения, которые предназначены для решения широкого круга различных задач по обработка информации в цифровой форме согласно заданной программе.
Основные функции микропроцессорной системы сводятся к приему данных (информации) от внешнего устройства, их обработке с помощью микропроцессора и выдаче результата обработки на внешнее устройство.
Рассмотрим в общих чертах особенности работы простейшей микропроцессорной системы (рис. 2.1.3), состоящей из центрального процессора, памяти и подсистемы ввода/вывода.
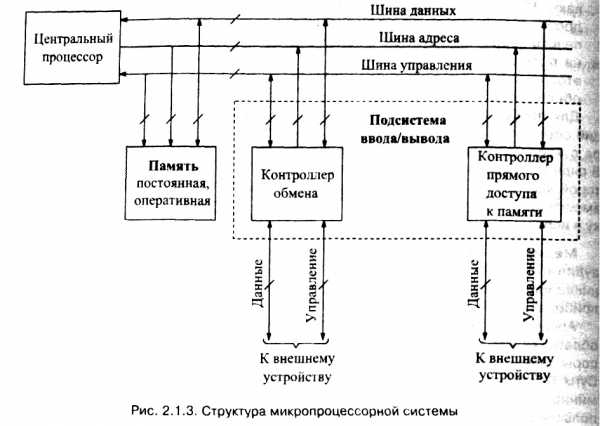 Подлежащая исполнению программа загружается в (оперативную) память. В процессе ее исполнения центральный процессор выдает на шину адреса адрес ячейки памяти, в которой хранится очередная команда, а на шину управления — сигнал, обеспечивающий ее чтение из памяти. Запрошенная команда по шине данных поступает в центральный процессор. Микропроцессор после расшифровки кода команды приступает к ее выполнению, если данные, над которыми должны быть выполнены действия, находятся в регистрах центрального процессора. В противном случае на шину адреса выставляется адрес ячейки памяти, на шину управления — сигнал чтения памяти, и только после получения требуемых данных команда будет исполнена. Затем центральный процессор приступает к обработке следующей команды, и процесс повторяется.
Подлежащая исполнению программа загружается в (оперативную) память. В процессе ее исполнения центральный процессор выдает на шину адреса адрес ячейки памяти, в которой хранится очередная команда, а на шину управления — сигнал, обеспечивающий ее чтение из памяти. Запрошенная команда по шине данных поступает в центральный процессор. Микропроцессор после расшифровки кода команды приступает к ее выполнению, если данные, над которыми должны быть выполнены действия, находятся в регистрах центрального процессора. В противном случае на шину адреса выставляется адрес ячейки памяти, на шину управления — сигнал чтения памяти, и только после получения требуемых данных команда будет исполнена. Затем центральный процессор приступает к обработке следующей команды, и процесс повторяется.
Для обмена данными между центральным процессором и внешними устройствами в подсистеме ввода/вывода предусмотрен контроллер обмена.
При программном обмене в контроллер обмена от центрального процессора, поступает информация о режиме обмена, содержащая код порта (регистра), направление обмена (от центрального процессора к внешнему устройству или от внешнего устройства к центральному процессору), число передаваемых бит, служебные символы и другие данные.
Непосредственный обмен данными происходит под действием сигналов управления, поступающих в контроллер обмена от центрального процессора и внешнего устройства.
При обмене по инициативе внешнего устройства микропроцессор переводится в состояние прерывания. Для этого внешнее устройство посылает в центральный процессор сигнал запроса на прерывание. В состоянии прерывания центральный процессор прекращает выполнение основной программы и приступает к исполнению команд прерывающей программы, которая хранится в (оперативной) памяти и обеспечивает обмен данными, требуемый внешнему устройству. По окончании прерывающей программы центральный процессор возвращается к выполнению основной программы.
Описанные способы обеспечивают низкую скорость обмена.
Для увеличения скорости обмена используется режим прямого доступа к памяти, который реализуется с помощью контроллера прямого доступа к памяти. Этот режим инициируется сигналом запроса на захват шин. После получения сигнала запроса центральный процессор пересылает по шине данных в контроллер прямого доступа информацию, необходимую для управления обменом (адрес ячейки памяти, в которой размещается первый байт записываемых или считываемых данных, общее число передаваемых байт, направление передачи и др.), и отключается от шины данных и шины адреса, предоставляя их контроллеру для организации обмена.
Обмен данными между внешним устройством и памятью осуществляется через контроллер. В процессе обмена контроллер прямого доступа к памяти выдает адреса ячеек памяти в шину адреса и сигналы чтения (записи) в шину управления. По завершении обмена центральный процессор получает сигнал от контроллера и переходит к выполнению основной программы.
pue8.ru
Основные типы диаграмм
В настоящее время, благодаря широкому использованию персональных компьютеров и пакетов специализированных прикладных программ, фактически не существует никаких ограничений, которые ранее диктовались трудоемкостью создания тех или иных типов диаграмм.
Фигурные диаграммы наиболее целесообразно применять при демонстрации каких-либо данных для широкой аудитории, не имеющей специальной подготовки (санитарно-просветительная работа, массовая агитация и т. п.) (рис. 1).
Рисунок 1. Патологическая пораженность (количество заболеваний) на 1000 студентов КрасГМУ по данным медицинского осмотра в 2009 году
Линейные диаграммы — наиболее распространенный вид диаграмм. Применяется для отображения практически любых статистических величин. Этот вид графических изображений относится к координатным диаграммам, т.е. диаграммам, использующим координатную систему. Для более наглядного отображения различий кроме обычных координатных осей рекомендуется использовать координатную сетку (рис. 2).
Рисунок 2. Динамика численности населения России с 1897 г. по 2004 г.
Столбиковые диаграммы представляют собой изображения различных величин в виде расположенных в высоту прямоугольников одинаковой толщины и разной высоты. Построение столбиковой диаграммы требует только одной масштабной шкалы, которая задает высоту столбика. Такие диаграммы применяются для отображения практически всех абсолютных и производных статистических показателей (рис. 3).
Рисунок 3. Динамика заболеваемости взрослого населения
Красноярского края в 2001-2006 гг.
Особым типом столбиковых диаграмм, который используется для иллюстрации плана, графика работ по какому-либопроектуявляетсяленточная диаграмма (диагра́мма Га́нта). При этом, каждый раздел плана изображается в виде столбика, пропорционального по размерам его длительности.
Для отражения изменений экстенсивных показателей более целесообразно использовать внутристолбиковые диаграммы (рис. 4).
Рисунок 4. Структура посещений врачей поликлиник Красноярского края в 1999-2003 гг.
Показательной для отображения экстенсивных показателей является секторальная диаграмма (рис. 5).
Рисунок 5. Структура причин смерти в Красноярском крае в 2006 г.
Для отображения сезонных и циклических явлений оптимальным вариантом является радиальная диаграмма (рис. 6).
Рисунок 6. Зависимость расстояния проживания от реки Енисей и числа посещений по поводу болезней лор-органов и органов дыхания на 1000 детей г. Красноярска (в 2005 году)
Главным критерием выбора той или иной диаграммы для отображения статистических показателей является наглядность и удобство анализа результатов. Например: если анализируется сравнительная заболеваемость мужчин и женщин, то более целесообразно представить попарно сгруппированные показатели мужчин и женщин.
Картограмма – это географическая карта или ее схема, на которой приведены определенные статистические данные (с помощью цветовой гаммы или различной штриховки территорий).
Картодиаграмма – это сочетание географической карты или ее схемы с различными диаграммами, представляющими статистические данные, относящиеся к определенным территориям.
Коробчатую диаграмму называют «коробкой с усами», «ящиком с усами», а по-английски boxplot. Данный тип визуализации данных одновременно изображает пять величин, характеризующих вариационный ряд: минимальное значение, первую квартиль (или 25 процентиль), медиану, третью квартиль (75 процентиль), максимальное значение. Таким образом, польза коробчатой диаграммы заключается в том, что на ней не только представлены основные характеристики распределения, но и доступен для оценки размах вариации, и ее асимметрия. Коробчатые диаграммы очень компактны, с их помощью удобно сравнивать характер распределения в нескольких рядах.
Коробчатая диаграмма может быть как вертикальной, так и горизонтальной. Основой ее является прямоугольник, нижняя (левая, если график горизонтальный) сторона – это нижний квартиль (Q1), а верхняя (правая) – верхний квартиль (Q3). Высота (длина) прямоугольника, таким образом, равна межквартильному интервалу (IQR). Черта поперек прямоугольника – это медиана распределения (рис. 7).
Рисунок 7. Особенности коробчатой диаграммы
Гистограмма характеризует распределение количественного признака, применяется для графического изображения интервальных рядов распределения. Внешне она представляет собой многоугольник, построенный с помощью смежных четырехугольников. Ширина основания каждого четырехугольника соответствует границам группы вариант. Высота столбика определяется частотой группы. На шкале «Х» в выбранном масштабе откладываются интервалы значений переменной. Интервалы не должны перекрывать друг друга или иметь пропуски возможных значений переменной. На оси «Х» указываются центр или границы каждого интервала. Ось «Y» служит шкалой плотности, т.е. на ней откладываются абсолютные (число наблюдений) или относительные значения (доля, процент наблюдений) на единицу шага значения переменной. В простейшем варианте (при условии одинаковой ширины интервалов на оси Х) шаг целого интервала принимается за 1.
Общее число (или долю) наблюдений характеризует не высота столбца, а его площадь. Высота столбца отражает плотность распределения признака в определенном интервале его значений. Площадь всех столбцов гистограммы должна равняться 100% (при относительной шкале плотности) или общей сумме наблюдений (при абсолютной шкале плотности).
Одновременное изображение на гистограмме кривой нормального распределения позволяет зрительно оценить, насколько эмпирическое распределение отличается от нормального (рис. 8).
Рисунок 8. Пример гистограммы с кривой нормального распределения: гистограмма возраста обследованных лиц
studfiles.net
Основные типы данных — books
Важно помнить, что общее правило “двигаться можно вниз, но не вверх”, применимо и во время анализа и визуализации данных. Если вы собираете переменную как нормативные данные, вы всегда можете позже сгруппировать данные для визуализации, если этого требует ваша работа. Если же вы собираете ее на более низком уровне измерения, позже вы не сможете перейти на более высокий уровень, не собрав больше данных. Например, если вы решили собирать данные о возрасте как порядковые данные, вы не сможете позже посчитать средний возраст, и ваша визуализация будет ограничена демонстрацией возрастных групп; вы не сможете показать возраст как непрерывные данные.
Если это не усложняет работу, собирать данные нужно на самом высоком уровне измерения, который вам может пригодиться позже. Мало что в работе с данными разочаровывает так, как понимание того, что вы собрали данные неправильным способом и не можете сделать то, что хотели.
Другие важные термины
Существуют еще термины, часто используемые применимо к видам данных. Мы решили не использовать их из-за небольшого расхождения во мнениях относительно их значений, но вы должны знать их возможные значения на случай, если встретите их в других источниках.
Категориальные данные
Ранее мы говорили о номинальных и порядковых данных как о способе распределить данные по категориям. Некоторые источники считают, что оба типа принадлежат к категориальным данным, где номинальные данные − неупорядоченные категориальные данные, а порядковые − упорядоченные. Другие источники относят к категориальным данным только номинальные, и считают, что понятия “номинальные данные” и “категориальные данные” − взаимозаменяемы. Эти источники относят порядковые данные к отдельной группе.
Качественные и количественные данные
Качественные данные, грубо говоря, относятся к нечисловым данным, в то время как количественные данные − числовые и, соответственно, поддающиеся счету. По отношению к этим терминам существует некое общее мнение. Определенные данные всегда считаются качественными, поскольку требуют предобработки или других методов анализа, чем количественные данные. Примерами могут считаться записи прямого наблюдения либо транскрипты интервью. Подобным образом, интервальные и нормативные данные всегда считаются количественными, поскольку они всегда числовые. Однако есть некое расхождение во мнениях относительно номинальных и порядковых типов данных. Некоторые источники называют их качественными, так как их категории описательные, а не числовые. Однако, поскольку эти данные можно посчитать и использовать для подсчета процентов, другие источники считают их количественными, поскольку они в этом смысле поддаются счету.
Чтобы избежать путаницы, мы будем придерживаться терминов, заданных в начале главы в течении всей книги, кроме главы о планировании и составлении опросов, где речь будет идти о полноформатных качественных данных. Если вам встретятся термины “категориальные данные”, “качественные данные”, или “количественные данные” в других источниках или в вашей работе, убедитесь, что понимаете, в каком значении они используются, и не полагайтесь на предположения!
books.irrp.org.ua
Основные типы данных
Данные в языке Си разделяются на две категории: простые (скалярные), будем их называть базовыми, и сложные (составные) типы данных.
Основные типы базовых данных: стандартный целый (int), вещественный с одинарной точностью (float) и символьный (char).
В свою очередь, данные целого типа могут быть короткими (short), длинными (long), и без знаковыми (unsigned), а вещественные – с удвоенной точностью (double).
Сложные типы – массивы, структуры (struct), объединения или смеси (union), перечисление (enum).
Данные целого и вещественного типов находятся в определенных числовых диапазонах так как занимают разный объем оперативной памяти:
Таблица 1
| Тип данных | Объем памяти (байт) | Диапазон значений |
| сhar | -128 …127 | |
| int | -32768…32767 | |
| short | 2(1) | -32768…32767(-128…127) |
| long | -2147483648…2147483647 | |
| unsigned int | 0…65535 | |
| unsigned long | 0…4294967295 | |
| float | 3,14*10-38…3,14*1038 | |
| double | 1,7 *10-308 1,7 *10308 |
4.3. Декларация (объявление) объектов
Все объекты, с которыми работает программа в Си необходимо декларировать, т.е. объявить компилятору об их присутствии в программе. При этом возможны две формы декларации:
– описание, не приводящее к выделению памяти;
– определение, при котором под объект будет выделен объем оперативной памяти, в соответствии с его типом; в этом случае объект можно сразу инициализировать, т.е. задать его начальное значение.
Кроме констант, которые можно задавать в исходном тексте, все объекты программы должны быть явно декларированы по следующему формату:
<атрибуты> <список ID объектов>;
элементы списка разделяются запятыми, а атрибуты – разделителями. Например: int i,j,k; float a,b;
Объекты программы в общем случае имеют следующие атрибуты:
<класс памяти> – характеристика способа размещения объектов в памяти (статическая, динамическая), определяет область видимости и время жизни переменной (по умолчанию – auto), данные атрибуты будут рассмотрены позже;
<тип> – характеристика механизма интерпретации данных, т.е. это совокупность информации о том, сколько объекту нужно выделить памяти, какой вид имеет представление информации и какие действия над ней допустимы (по умолчанию – int).
Класс памяти и тип – атрибуты необязательные и могут отсутствовать, тогда их значения установятся по умолчанию.
Примеры декларации простых объектов:
int i,j,k;
char r;
double gfd;
Рассмотрим основные базовые типы данных более подробно.
4.4. Данные целого типа (int)
Тип int – целое число, обычно соответствующее естественному размеру целых в используемой ЭВМ. Квалификаторы short и long, которые можно использовать с типом int, указывают на различные размеры целых, т.е. определяют размер памяти, выделяемый под переменные (табл.1).
Примеры: short int x;
long int x;
unsigned int x = 8; (декларация с одновременной инициализацией числом 8).
Атрибут int в таких ситуациях может быть опущен.
Атрибуты signed и unsigned показывают, как интерпретируется старший бит числа, как знак или как часть числа:
| int | Знак | Значение числа | |
| 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 | – номера битов |
| unsigned int | Значение числа |
| 15 0 |
| long | Знак | Значение числа |
| 30 0 |
| unsigned long | Значение числа |
| 31 0 |
Если указан только атрибут int, это означает – short signed int.
4.5. Данные символьного типа (char)
Символьная переменная занимает в памяти 1 байт и представляется кодом от 0 до 255. Закрепление конкретных символов за кодами производится кодовыми таблицами.
Для персональных компьютеров наиболее распространена ASCII (American Standard Code for Information Interchenge) таблица кодов (Приложение 1). Данные типа char рассматриваются компилятором как “целые”, поэтому возможно использование signed char (по умолчанию) – символы с кодами от -128 до +127 (т.е. только символы с кодами до 127) и unsigned char – символы с кодами от 0 до 255 (в том числе и русские).
Примеры:
char res, simv1, simv2;
char let = ‘s’; (декларация с одновременной инициализацией символом s).
4.6. Данные вещественного типа (float, double)
Данные вещественного типа в памяти занимают, соответственно, float – 4 байта; double – 8 байт; long double (повышенная точность) – 10 байт. Для размещения данных типа float обычно 8 бит выделено для представления порядка и знака и 24 бита под мантиссу.
| Тип | Точность (мантисса) | Порядок |
| float | 7 цифр после запятой | ± 38 |
| double | ± 308 | |
| Long double | ± 4932 |
Похожие статьи:
poznayka.org